core币如何质押教程?
答:core币如何质押教程步骤如下,**步打开:节点质押地址。
第二步:找到21个节点,挑选一个质押,不要找那种小节点,节点掉线会扣你的奖励,**找官方节点。
第三步:点质押,输入数量即可。
如何才能深度学习呢?
学习和深度学习,是两个**不同的概念
时下,很多人都会存在一个学习误区:把持有当作拥有,把阅读、学习本身,当作学习的效果。
当说起学习,很多人都会自骄的说,一年读了XX本书,学到了XX个知识,并且附上详尽的学习笔记和思维导图。但他们都弄错了学习本身的含义,学习并不是追求你存货多少,而是需要把学到的东西,运用到生活、工作当中去,或者至少对你个人有所启发。

如何才可以做到深度学习?
不轻易下**一个断言,**保持这思考的习惯,寻求事物背后的规律。深度学习要求你不断的主动去思考,把知识做到内化于己。

1.用自己的话复述。所有的知识都不需要死记硬背,而是试着在理解的基础上,把它表达出来,就好像你把它教给一个**不明白的人一样。这样,通过不断的讲述,让你的大脑保持思考的习惯,把知识点**内化。
2.发散联想。学习的过程中,时常会遇到一些很有趣的知识点,或者一些很实用的知识点。此时,你要学会发散性思维,举一反三,把它相关联的知识点都罗列出来,做到系统化、**化,这是一种更有效的学习方法。

3.用主题去统领内容。因为工作需要,当你需要去学习某个技能或知识时,你可以先罗列出你需要学习的各点各面,再去寻找一切相关的资料,把各种碎片化的信息整合起来,成为自己的知识体系。
4.丰富知识网络。有了以上3个步骤之后,你还要定期对自己的知识进行审视、总结,勾画出一个思维导图,相信我,你又可以得到新的观点,以此不断的进行自我迭代。
实现深度学习的关键在于运用,我给大家提供了几个运用知识的具体方案:

一 把所学知识运用到相对应的环境中去。
我们学所有的知识,目的都在于运用,把所学到的知识运用到对应的环境中去,解决具体的问题,这才是知我所学知识的价值所在。
比如我们在学校,把所学到的各个知识点,运用到练习或者是考试中去。能够解决问题的知识才是真正属于自己的知识,否则懂再多的理论也是纸上谈兵。

二 运用所学的知识,举一反三,作为学习新内容的基础。
所有的内容都有一个由浅入深的过程,把前面简单的知识学会了,才有可能去学习更加高深的知识。
同样的也只有真正的掌握了前面的知识,才有可能融会贯通,再继续学习更加高深的内容,从而完成知识的更新迭代。

三 把所学到的知识分享给他人。
这个知识我会背了,会解决问题了,这还只是最基本的学习。真正的懂是能够分享给别人,并且别人也能听懂,这才是真正的学会了这一项知识。
每个人的基础和接受能力都是不同的,正确分析他知识水平来,灵活运用所学的知识,来制定分享方案,这对所学的知识,又提高了一个更高的要求。能够做到这一点,才算是真正完成了深度学习。
Medium上获得超过一万五千赞的深度学习入门指南,结合图文为你缕清深度学习中的各个基础概念的内涵。
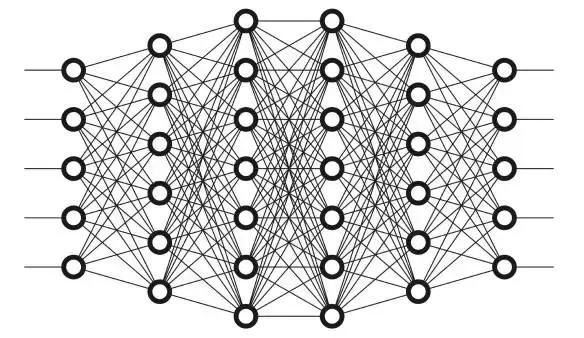
Image credit: Datanami
人工智能(AI)
()
和机器学习(ML)
()
都属于目前**门的话题。
在日常生活中,AI这个术语我们随处可见。你或许会从立志高远的开发者哪那里听说她(他)们想要学习AI。你又或许会从运营者那里听到他们想要在他们的的服务中实施AI。但往往这些人中的绝大多数都并不明白什么是AI。
在你阅读完这篇文章之后,你将会了解AI和ML的基本知识。而更重要的是,你将会明白深度学习(),这类**门的机器学习,是如何运作的。
这篇教程适用于所有人,所以本文并没有涉及**数学。
背景
理解深度学习如何工作的**步是掌握下列重要术语之间的区别。
人工智能(AI)v.s.机器学习(ML)
人工智能是人类智能在计算机上的复制。
AI的研究之初,那时的研究人员尝试着复制人类智能来完成像玩游戏这样特定的任务。
他们引入了大量的计算机需要遵守的规则。有了这些规则,计算机就有了一份包含各种可能行动的清单,并基于这些规则作出决定()。
机器学习,指的是机器使用大量数据集而非硬编码规则来进行学习的能力。
ML允许计算机通过自身来学习。这种学习方法得益于现代计算机的强大性能,性能保证了计算机能够轻松处理样本数巨大的数据集。
监督学习 v.s. 非监督学习
监督学习
()
指的是利用已标注数据集进行的学习,该数据中包含输入和期望输出。
当你利用监督学习来训练AI时,你提供给它一份输入,并告诉它预期的输出。
如果AI所生成的输出是错误的(译者注:与期望输出不同),它将重新调整计算(注:应该是对公式的参数进行重新计算)。这个过程将会在数据集上迭代运行,直到AI不再犯错误。
预测天气的AI便是监督学习的一个典型例子。它通过学习过往数据来预测未来天气。该训练数据拥有输入(气压,湿度,风速)和输出(温度)。
非监督学习
()
是机器学习应用没有指定结构的数据集来进行学习的任务。
当你应用非监督学习来训练AI时,你可以让AI对数据进行逻辑分类。
电商网站上的行为预测AI便是非监督学习的一个例子。它无法通过拥有输入和输出的已标注数据集来进行学习。相反地,它在输入数据上创建它自己的分类。它将会告诉你哪一种用户最可能购买差异化的商品。
深度学习又是如何运作的呢?
现在你已经准备好去理解什么是深度学习,以及它是如何运作的。
深度学习是机器学习中的一种方法。在给予它一组输入后,它使我们能够训练AI来预测结果。监督学习和非监督学习都能够用来训练AI。
我们将通过建立一个假设的机票价格预估系统来阐述深度学习是如何运作的。我们将应用监督学习方法来训练它。
我们想要该机票价格预估系统基于下列输入来进行预测(为了简洁,我们除去了返程机票):
起飞机场
到达机场
起飞日期
航空公司
神经网络
接下来我们将视角转向我们的AI的大脑内部。
和动物一样,我们预估系统AI的大脑中有神经元。将它们用圆圈表示。这些神经元在内部都是相互连接的。
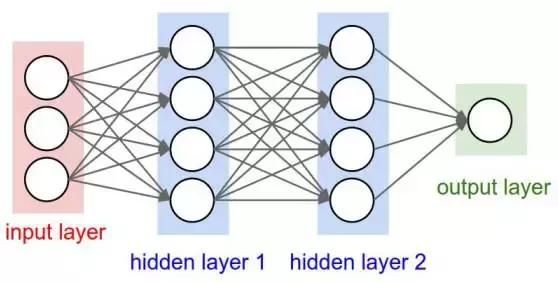
Image credit: CS231n
这些神经元又被分为三种层次:
输入层
隐藏层
输出层
输入层接收输入数据。在本案例中,在输入层中有4个神经元:起飞机场,到达机场,起飞日期以及航空公司。输入层将输入传递给**个隐藏层。
隐藏层针对我们的输入进行数**算。创建神经网络的一大难点便是决定隐藏层的层数,以及每层中神经元的个数。
深度学习中的“深度”所指的是拥有多于一层的隐藏层。
输出层返回的是输出数据。在本案例中,输出层返回的是价格预测。
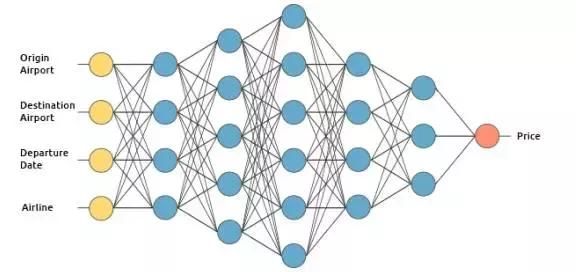
那么它到底是如何来运算价格预测的呢?
这便是我们将要揭晓的深度学习的奇妙之处了。
每两个神经元之间的连接,都对应着一个权重。该权重决定了输入值的重要程度。初始的权重会被随机设定。
当预测机票价格时,起飞日期是决定价格的最重要的因素之一。因此,与起飞日期这个神经元相连的连接将会有更高的权重。
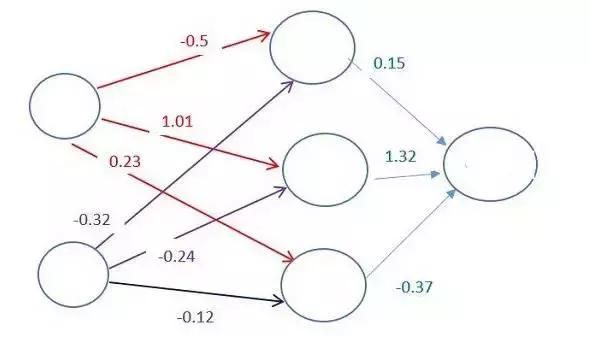
Image credit: CodeProject
每个神经元都有一个激活函数()。若没有数学推导,这些函数**晦涩难懂。
简而言之,激活函数的作用之一便是将神经元的结果“标准化”。
一旦一组输入数据通过了神经网络的所有层,神经网络将会通过输出层返回输出数据。
一点也不复杂,是吧?
训练神经网络
训练AI是深度学习中最难的部分了。这又是为什么呢?
你需要一个庞大的数据集
你还需要强大的算力
对于我们的机票价格预估系统,我们需要得到过往的票价数据。由于起始机场和起飞时间拥有大量可能的组合,所以我们需要的是一个非常庞大的票价列表。
为了训练机票价格预估系统的AI,我们需要将数据集的数据给予该系统,然后将它输出的结果与数据集的输出进行比对。因为此时AI仍然没有受过训练,所以它的输出将会是错误的。
一旦我们遍历完了整个数据集,我们便能创造出一个函数,该函数告诉我们AI的输出和真实输出到底相差多少。这个函数我们称为损失函数。
在理想情况下,我们希望我们的损失函数为0,该理想情况指的是AI的输出和数据集的输出相等之时。
如何减小损失函数呢?
改变神经元之间的权重。我们可以随机地改变这些权重直到损失函数足够小,但是这种方法并不够**。
取而代之地,我们应用一种叫做梯度下降()的技巧。
梯度下降是一种帮助我们找到函数**值的技巧。在本案例中,我们寻找损失函数的**值。
在每次数据集迭代之后,该方法以小增量的方式改变权重。通过计算损失函数在一组确定的权重集合上的导数(梯度),我们便能够知悉**值在哪个方向。
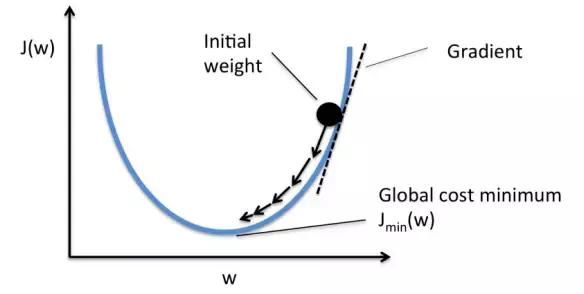
Image credit: Sebastian Raschka
为了**化损失函数,你需要多次迭代数据集。这便是需要高算力的原因了。
利用梯度下降更新权重的过程是自动进行的。这便是深度学习的魔力所在!
一旦我们训练好机票价格预估的AI之后,我们便能够用它来预测未来的价格了。
拓展阅读
神经网络有非常多的种类:用于计算机视觉()的卷积神经网络()以及应用于自然语言处理()的循环神经网络()。
如果你想要学习深度学习的技术细节,我建议你参加一个在线课程。
吴恩达()的深度学习专项课程()是当下**的深度学习课程之一。如果你并不需要一个证书,你便可以免费旁听这门课程。
小结
1. 深度学习应用神经网络来模仿动物智能。
2. 神经网络中有三个层次的神经元:输入层、隐藏层以及输出层。
3. 神经元之间的连接对应一个权重,该权重决定了各输入数据的重要程度。
4. 神经元中应用一个激活函数来“标准化”神经元输出的数据。
5. 你需要一个庞大的数据集来训练神经网络。
6. 在数据集上迭代并与输出结果相比较,我们将会得到一个损失函数,损失函数能告诉我们AI生成的结果和真实结果相差多少。
7. 在每次数据集的迭代之后,都会利用梯度下降方法调整神经元之间的权重,以减小损失函数。